Activation Repartitioning #8877
Conversation
src/Orleans.Runtime/Placement/Rebalancing/ActiveRebalancerGateway.cs
Outdated
Show resolved
Hide resolved
src/Orleans.Runtime/Placement/Rebalancing/ActiveRebalancerGrain.cs
Outdated
Show resolved
Hide resolved
src/Orleans.Runtime/Placement/Rebalancing/ActiveRebalancerGrain.cs
Outdated
Show resolved
Hide resolved
src/Orleans.Runtime/Placement/Rebalancing/ActiveRebalancerGrain.cs
Outdated
Show resolved
Hide resolved
|
@gfoidl please have a look again, thx! |
src/Orleans.Runtime/Placement/Rebalancing/ActiveRebalancerGrain.cs
Outdated
Show resolved
Hide resolved
3148fac
to
e50a28a
Compare
src/Orleans.Runtime/Placement/Rebalancing/ActiveRebalancerGrain.cs
Outdated
Show resolved
Hide resolved
65d037d
to
2fb6430
Compare
cef7537
to
5600ca1
Compare
|
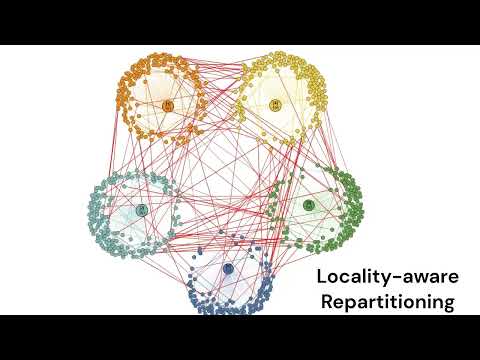
Here is a demo showing this in action on a 5-node cluster: |
ea708de
to
6996c2c
Compare
5fcc61a
to
8abbc6f
Compare
39cf649
to
42b241e
Compare
|
Here's the snippet I wrote about Activation repartitioning from the v8.2.0 release notes. Activation repartitioningActivationRepartitioning.mp4
Ledjon Behluli and @ReubenBond implemented activation repartitioning in #8877. When enabled, activation repartitioning collocates grains based on observed communication patterns to improve performance while keeping load balanced across your cluster. In initial benchmarks, we observe throughput improvements in the range of 30% to 110%. The following paragraphs provide more background and implementation details for those who are interested. The feature is currently experimental and to enable it you need to opt-in on every silo in your cluster using the #pragma warning disable ORLEANSEXP001 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.
siloBuilder.AddActivationRepartitioner();
#pragma warning restore ORLEANSEXP001 // Type is for evaluation purposes only and is subject to change or removal in future updates. Suppress this diagnostic to proceed.The fastest and cheapest grains calls are ones which don't cross process boundaries. These grain calls do not need to be serialized and do not need to incur network transmission costs. For that reason, collocating related grains within the same host can significantly improve the performance of your application. On the other hand, if all grains were placed in a single host, that host may become overloaded and crash, and you would not be able to scale your application across multiple hosts. How can we maximize collocation of related grains while keeping load across your hosts balanced? Before describing our solution, we need to provide some background. Grain placement in Orleans is flexible: Orleans executes a user-defined function when deciding where in a cluster to place each grain, providing your function with a list of the compatible silos in your cluster, that is, the silos which support the grain type and interface version which triggered placement. Grains calls are location-transparent, so callers do not need to know where a grain is located, allowing grains to be placed anywhere across your cluster of hosts. Each grain's current location is stored in a distributed directory and lookups to the directory are cached for performance. Resource-optimized placement was implemented by @ledjon-behluli in #8815. Resource-optimized placement uses runtime statistics such as total and available memory, CPU usage, and grain count, collected from all hosts in the cluster, smooths them, and combines them to calculate a load score. It selects the least-loaded silo from a subset of hosts to balance load evenly across the cluster1. If the load score of the local silo is within some configured range of the best candidate's load score, the local silo is chosen preferentially. This improves grain locality by leveraging the knowledge that the local silo initiated a call to the grain and therefore has some relation to that grain. Ledjon wrote more about Resource-optimized placement in this blog post. Originally, there was no straightforward way to move an active grain from one host to another without needing to fully deactivate the grain, unregister it from the grain directory, contend with concurrent callers on where to place the new activation, and reload its state from the database when the new activation is created. Live grain migration was introduced in #8452, allowing grains to transparently migrate from one silo to another on-demand without needing to reload state from the database, and without affecting pending requests. Live grain migration introduced two new lifecycle stages: dehydration and rehydration. The grain's in-memory state (application state, enqueued messages, metadata) is dehydrated into a migration packet which is sent to the destination silo where it's rehydrated. Live grain migration provided the mechanism for grains to migrate across hosts, but did not provide any out-of-the-box policies to automate migration. Users trigger grain migration by calling Finally, we have the pieces in place for activation repartitioning: grain activations are load-balanced across the cluster, and they are able to migrate from host to host quickly. While live grain migration gives developers a mechanism to migrate grain activations from one host to another, it does not provide any automated policy to do so. Remember, we want grains to be balanced across the cluster and collocated with related grains to reduce networking and serialization cost. This is a difficult challenge since:
Folks at Microsoft Research studied this problem and proposed a solution in a paper titled Optimizing Distributed Actor Systems for Dynamic Interactive Services. The paper, dubbed ActOp, proposes a decentralized approximate solution which achieves good results in their benchmarks. Their implementation was never merged into Orleans and we were unable to find the original implementation on Microsoft's internal network. So, after first implementing resource-optimized placement, community contributor @ledjon-behluli set out to implement activation repartitioning from scratch based on the ActOp paper. The following paragraphs describe the algorithm and the enhancements we made along the way. The activation repartitioning algorithm involves pair-wise exchange of grains between two hosts at a time. Silos compute a candidate set of grains to send to a peer, then the peer does similarly, and uses a greedy algorithm to determine a final exchange set which minimizes cost while keeping silos balanced. To compute the candidate sets, silos track which grains communicate with which other grains and how frequently. The whole graph would be unwieldy, so we only maintain the top-K communication edges using a variant of the Space-Saving2 algorithm. Messages are sampled via a multi-producer, single consumer ring buffer which drops messages if the partition is full. They are then processed by a single thread, which yields frequently to give other threads CPU time. When the distribution has low skew and the K parameter is fairly small, Space-Saving can require a lot of costly shuffling at the bottom of its max-heap (we use the heap variant to reduce memory). To address this, we use Filtered Space-Saving3 instead of Space-Saving. Filtered Space-Saving involves putting a 'sketch' data structure at the bottom of the max heap for the lower end of the distribution, which can greatly reduce churn at the bottom and improve performance by up to ~2x in our tests. If the top-K communication edges are all internal (eg, because the algorithm has already optimized partitioning somewhat), silos won't find many good transfer candidates. We need to track internal edges to work out which grains should/shouldn't be transferred (cost vs benefit). To address this, we introduced a bloom filter to track grains where the cost of movement is greater than the benefit, removing them from the top-K data structure. From our experiments, this works very well with even a 10x smaller K. This performance improvement will come with a reduced ability to handle dynamic graphs, so in the future we may need to implement a decay strategy to address this as the bloom filter becomes saturated. To improve lookup performance, @ledjon-behluli implemented a blocked bloom filter4, which is used instead of a classic bloom filter. Footnotes
|
Intro
This PR adds "Active Rebalancing" which is a mechanism to automatically and dynamically migrate grain activations based on the locality-aware partitioning algorithm which is described in section 4 of this paper: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/06/eurosys16loca_camera_ready-1.pdf
Implementation details have been provided extensively via comments in the code itself, but below we will discuss some of the overarching points, and decisions.
Components
ActiveRebalancerGrainThis is the main component which determines both: when & how the rebalancing will occur. It was meant to be implemented as a
GrainServicebut due to the fact that aGrainServiceis aSystemTarget, it means the by default those are always reentrant, which is not fitted for this functionality. Therefor this component is a normal grain which is activated locally upon each silo startup via theActiveRebalancerGateway.This grain is called periodically by an internal timer based on the time spans which are set via the
ActiveRebalancingOptions.We force reentrancy of the timer by means of executing its
TriggerExchangeRequestas a reference to the grain itself. We do this so further edge (communication links) recordings will be stopped until the protocol finishes (if it is self-triggered, or by another rebalancer grain from another silo). We do this to avoid changing the counters while the protocol is running, not because of thread-safety reasons (since it runs under the grainsTaskScheduler), but due to logical reasons.The rebalancer grain as a mechanism which breaks out of potential deadlocks on which the grain might enter. This could happen when a rebalancer grain is currently performing an
AcceptExchangeRequest(the counterpart ofTriggerExchangeRequest)with the another silo, while that same silo is doing the same operating with this grain.In addition to breaking out of the deadlock, when that happens the timer of the broken-out silo is slightly shifted from the randomly picked due time, in order to further contribute on avoid these "mutual exchange attempts".
ActiveRebalancerGatewayThis is a component which sits between the networking layer and the rebalancer grain. It is itself a lifecycle participant and
is responsible for 2 main operations:
Quickly filter out any unwanted messages that come from the networking layer. Usually these are system messages, but there are also different cases which are well elaborated in the code comments.
Messages of interest are converted into another format which the rebalancer understands, and these are forwarded into a
BoundedChannelwhich is configured for maximum parallelism, and drop the oldest messages in case new once arrive in case the channel is full (currently configured to hold up to 100_000 items, but I am open to changing that). This technically is not 100% NEEDED, due to the fact that this is an extremally hot path any optimization is good to have. It also supports dropping messages, which is fine for our case, since either way the communication edge recorded are filtered by a probabilistic data structure.ActiveRebalancerExtensionA
GrainExtensionwhich is used to decouple some cross-cutting concerns out of theActiveRebalancerGrainso it stays focused on its main logic. More information about these concerns are given in the code comments. In addition to those it is used to swap out the current frequency counters with empty once, which is used for automated tests.Note that the extension is called upon starting the rebalancer gateway.
FrequencySinkDue to the enourmous amount of messages which are anticipated to flow through the system, any attempt to record all of those is destined to fail, for 2 reasons:
The
FrequencySinkis a component which implements a modified version of the space-saving algorithm which is described in section 3.1 this paper: https://www.cse.ust.hk/~raywong/comp5331/References/EfficientComputationOfFrequentAndTop-kElementsInDataStreams.pdfIn addition to the algorithm itself, further optimizations in the form of a updatable min-heap structure has been employed in order to minimize time spent when the data structure is full, and lowest value counters need to be dropped/replaced with new incoming data. While the heap structure has been modified a lot to be optimized for our specific needs, a lot of credit must be given to: https://github.com/DesignEngrLab/TVGL/blob/master/TessellationAndVoxelizationGeometryLibrary/Miscellaneous%20Functions/UpdatablePriorityQueue.cs
DefaultImbalanceRuleThis is the default implementation of the
IImbalanceToleranceRuleinterface, which is publicly available and is meant to be implement by users, in order to fit their specific needs.Before we elaborate the default rule, we should point out that
IImbalanceToleranceRulerepresents a rule that controls the degree of imbalance between the number of grain activations (that is considered tolerable), when any pair of silos are exchanging activations.This is part of the ActOp paper, and is a key component on making sure that the exchange protocol does not overload a single silo due to cutting remote connection and pushing them all towards a single one.
Back to the default rule - This is a tolerance rule which is aware of the cluster size (number of active silos). This has been specifically crafted so that the tolerance is higher when the number of silos is slow(er), and becomes tighter when the number increases.
Usually system deployed are in the range of 1-10 silos, and its rare that system go upwards of 100+ silos. With this "guess" the default rule "rewards" smaller cluster with a higher tolerance, and "punishes" the once which are larger in size. It is sound to do this, because if its fixed, and the cluster has more silos, it means that there is a greater overall imbalance in the cluster.
The rule follows a piecewise, inverted, scaled and shifted, sigmoid function which maps the number of active silos to different tolerance levels. Below we can see a graph on how this changes, where the x-axis represents the number of silos, and the y-axis is the percentage deviation from the baseline value (set to 10).
For example: when the number of silos = 2, the tolerance is ~ 1000 activation difference allowed between any pair of silos, and if the number of silos >= 100 the tolerance is ~ 100 activation difference (a 10x reduction factor)
Note that I am open to change this if there is a better suited, generic rule!
ActiveRebalancingOptionsThis class is used to control the behavior of the rebalancer(s), and while it has been decorated with plentiful comments on the meanings of each of the properties, 2 things are worth pointing out here:
The
DueTimeare given in a range, as opposed to a single value. This has been done so that the actual due time is picked randomly between that range, so we do a better job at avoiding so called "mutual exchange attempts", where 2 silos begin the exchange protocol between each other and the same time. And while there exists a mechanism (mentioned above in theActiveRebalancerGrainsection) to break those silos out of this state, it does not hurt to avoid this as much as possible.The default values are picked "to my best reasoning" and I am open to changing them if more sound arguments are presented. Note that the
DEFAULT_RECOVERY_PERIODis picked in accordance with the ActOp paper.Configuration
While operational, it is fair to say that this feature needs a good amount of testing, therefor it is opt-in!
In order for users to make use of it, all they have to do is add the extension method
AddActiveRebalancingwhen configuring theISiloBuilder, or potentially use the generic version which accepts an implementation ofIImbalanceToleranceRulespecificallyAddActiveRebalancing<TRule>.The options can be configured (if defaults are not suited to users needs) as any other options in the framework via
hostBuilder..Configure<ActiveRebalancingOptions>(o => {...})Additional Information
The main point of the algorithm is to break remote actor communications and convert those into local calls, while adhering to the imbalance tolerance defined above.
The algorithm determines the most heavies communication edges based on 2 factors: number of connections & frequency of message exchange between the connections.
SystemTargetssuch are stream puling agents, grain services, but also stateless worker grains, are also supported, but since they represent immovable components, they won't be treated as sources of migration, instead they are treated as potential targets towards which other (movable) grains can be migrated.In addition to these immovable components, the user are free to decorate their own (inertly movable) grains via a special attribute call
ImmovableAttributewhich will instruct the runtime to not move activations of such grain types. Yet other movable grain can be moved towards them.Tests
The solution is covered by some overarching tests (which could be improved ofc)

Examples
Below we can see some examples of isolated graphs which represent a microsome view of much larger graphs, and the overall working principles of the algorithm.
Microsoft Reviewers: Open in CodeFlow